浅聊一下计算机乱码这些事。
不知道你有没有见过全是 锟斤拷 的文本文件或是全是 ⊠ 游戏对话,抑或是满屏 � 的错误网页,又比如类似这样文字夹杂着字母符号根本看不懂的东西。
这些东西被称之为“乱码”,狗屁不通,让人梦回火星文年代。
例如 杩芥ⅵ宸ュ潑 就是乱码了的 追梦工坊 四个字
所谓“锟斤拷”就是因为字符集编码不兼容等原因而显示的乱码,常见的还有“烫烫烫”、”屯屯屯“等,下面我将从编码格式开始讲起,跟大家解释“锟斤拷”的由来。
字符编码
字符与字符集
一个汉字,一个字母,一个数字,或者是一个标点符号,在计算机系统里都属于一个字符
而很多的字符组合起来的集合就叫做字符集,借用数学上集合的概念,{a,b,c,d,A,B,C,D,一,二,三,四,简,体,字,和,各,種,繁,體,字,。,?,!} 就算一个字符集,当然实际电脑上的字符集肯定远远不止我举例演示的这些。
人类世界又海量的字符集,例如我们最常见的汉字,字母,数字,还有诸如楔形文字,日语,韩语一类的字符集,他们本都写在纸上,刻在泥板或者石头上,而这些所有的字符,我们的”渣渣“计算机一个都不认识。
你肯定了解过,计算机只认二进制,它只能以 bit 的形式记录 0 和 1。那么为了让计算机识字,我们就需要用计算机认识和懂得的 0 和 1 来编码这些文字。
那就打开 EXCEL,把你要用的字打进格子里。

(注意将 ABCDEFG 对应替换为 1234567)
此时如果你想要显示 Hi,中国科技 这几个字符就只需要以计算机能懂的二进制告诉计算机显示 12 23 25 14 24 61 71 这几个字符,经过计算机”一通乱算”,就能正常显示为 Hi,中国科技,以此为基础,就能拓展出多种不同的字符集。当然正经字符集不会像我演示的这样没有规则,十分杂乱。
上面提到的字符坐标,例如 赵 所对应的 55 就叫码位,这整一张表中能容纳的字符数量就叫码空间,码空间越大,容纳的字符就越多,能显示的字就越多。
现实世界中,计算机储存字符的单位是 Byte 字节,每 Byte 都由 8 个二进制位也就是由 8 bit 组成,那么理论上 1 Byte 有 28 也就是 256 种不同的状态。
用一个字节来编码字符就能显示 256 种不同的字符,听起来很少,但对于只有 26 个字母的英文而言,绰绰有余。所以在上世纪六十年代,美国人搞出了 ASCII(American Standard Code for Information Interchange 美国信息交换标准代码)
ASCII
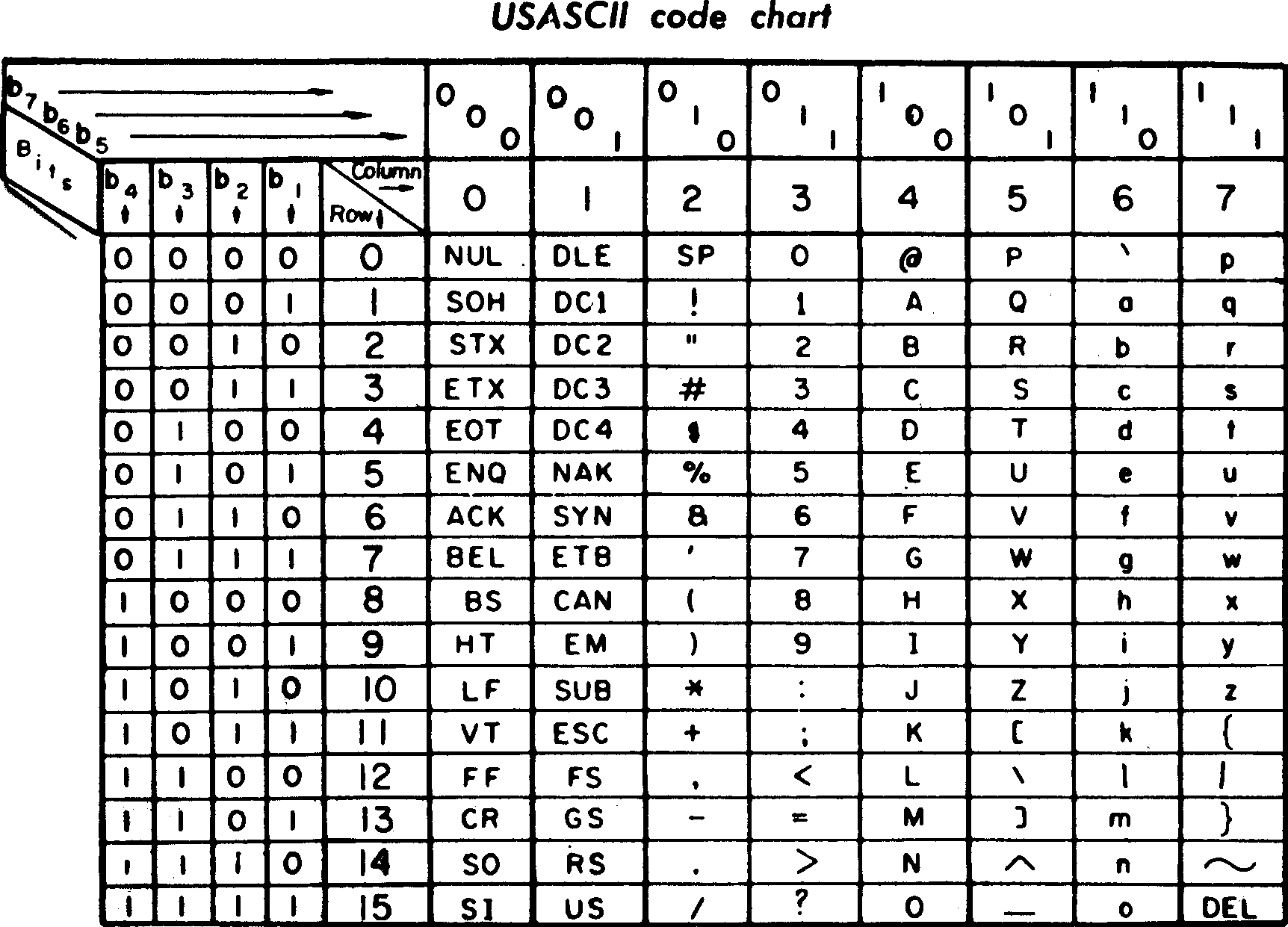
ASCII 一共收录了 128 个字符,包括大写字母,小写字母,标点符号,数字等,还有很多像 ESC,换行这类看不见的控制字符。
到现在为止,事情还很简单,无非就是将例如字符 A 编码成 65 再换成二进制 1000001,发送给电脑,电脑再根据 1000001 找出字符集里的对应的字符 A,按编号调用字符,就能在屏幕上显示出来。
一切看起来都很简单,完美
而所有完美都是易碎的。
EASCII
世界各国有不同的语言,光联合国五大常任理事国就有四门语言(哪国没有自己的语言我不说,大家都清楚),举个简单的例子
中文:科技
英语:Technology
俄语:технолог
法语:Science et当各国都要跑入信息化的时候,文字显示的乱纪元就从此开始了
刚刚不是说过英语字符少吗,256 个字符才用了一半就没了,还剩整整半张的空表

于是各国纷纷往这半张空表里填自己的内容,将 ASCII 拓展成 EASCII(拓展美国信息交换标准代码),也就是用剩下的 128 个空格来表示其他字符,比如希腊字母 αβγδ,再比如 ∠⊥∩ 等等(只是举例,不代表实际情况)。
那么,问题就出现了。
各国的 EASCII 后128 个字符都不太一样,一共搞出了 200+ 的 EASCII,互不兼容,就算是统一串编码在不同 EASCII 中代表的字符也不同,例如 I7 这一格,俄罗斯填了 л,西班牙填了 í,越南又填了 ệ,到了泰国又被填上 ท(只是举例,不代表实际情况)那么当一篇好好的文档出了国,或者干脆同一台电脑换了种语言,其内容就相去甚远了,这还算好的。
GB2312-80
当信息高速公路修到中日韩的时候,就要面临一个更复杂的问题:汉字。
汉字文化源远流长,总数量那实在是多,我国 1980 年公布的 GB2312-80 中列举出最最常用的基本汉字就超过了 6500 个。
对于这成千上万个汉字,1 Byte 的 256 字符根本不够用,所以 GB2312 中用两个字节来表示一个字符,这样理论上就可以表示 216 也就是 65536 个字符。
例如:
, 英文半角逗号 00101100
, 中文全角逗号 1111111100001100而这 6500 多个汉字只是最最常用的,其实根本不够用,比如像喆,頫,祎这些人名中的常见字甚至都不包括在内。那字符集中没有这个字怎么办呢?那就打不出来。
陶�,赵孟�,鞠婧�,大型猜人现场(
所以在过去如果你叫张暐(简体:日+韦,到现在还没收)的话,你只能改成满大街遍地是的张伟。
在 2009 年,广州番禺的一个村子,由于名字里有一个电脑打不出来的生僻字(门内唐,现在也还没收),只能改性唐,才为村里人办下二代身份证。
似乎看起来十分完美,但这条路上根本没有所谓完美一说。
GBK
汉字虽然起源于中国,然而不止中国一家用,朝鲜,日本,不同国家地区还有多种不同写法,就连中国的香港和台湾都不一样。
比如说常见的“群”字,“里”字和“叹”字:
大陆简体:群 里 叹
香港繁体:羣 裡 歎
台湾正体:群 裏 嘆日本有日本汉字,朝鲜有朝鲜汉字,各家写法不同,编码思路不同,都优先考虑本地人使用方便,然后又是十几二十几套兼容性有是有,但只有一点点的编码标准。
后来微软被逼急了,综合各国编码,以 GB2312 为本拓展出了 GBK 编码,加入了一些繁体汉字,后来就成了汉字内码拓展规范 GBK(Guojia Biaozhun Kuozhan 国家标准扩展)
另外要注意的是 GBK 是“技术规范指导性文件”,不属于国标。
这种新三年旧三年,缝缝补补又三年的操作也成了后来很多乱码的来源之一。
Unicode
总而言之,随着计算机快速普及,各种编码格式编码规范已经乱的不能再乱了,我们早晚得想办法解决这个问题。
摆在面前的解决办法有两种:
第一:几颗大伊万一扔,世界清净,一切重开。
第二:搞一个超~~~~~~(无限延音)大的字符集,把所有字符全部收录进去
于是,在 1991 年,Unicode 万国码应运而生。
Unicode 一上来就收录了 25 种文字 28000+ 字符,随着版本迭代,Unicode 现在已经包含 1114112 个码位(数据截至今年 10 月 10 日),包括中文,日文,韩文,甚至古象形文字和 Emoji,是当之无愧的万国码。
而因为 Unicode 是一直在更新的,在这个过程中,肯定有一些较新的字符无法被表示。或者即使 Unicode 发布了新版纳入了某个文字,但是很多软件系统并未升级 Unicode 版本,也会出现这样的问题。就像老手机不支持 Emoji 一样。
即使 Unicode 做了很多努力,但文字显示的乱纪元却仍然没有结束。
虽然 Unicode号称万国码(也叫统一码),但一统江湖哪有这么简单。
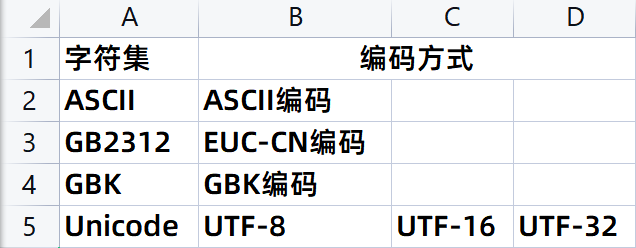
作为万国码,Unicode拥有多种编码方式,最常用的就是 UTF-8 编码。
编码的重要性不言而喻,上面也说过了,同一串二进制信息经过不同编码会显示不同字符,如果用错误编码打开文本,就会出现乱码。
在中文世界里 Unicode 和 GBK 都有很多使用者,而当 Unicode 和 GBK 激情碰撞后,噩梦般的上古神器【锟斤拷】就出现了。
因为很多操作系统都应用的是 GBK 编码,而 MacOS 和很多软件用的都是 UTF-8,你随随便便就能整出一连串的“锟斤拷”。
锟斤拷
Unicode 中定义了一个特殊字符 �(U+FFFD),所有无法表示的字符都会通过这个字符来表示。
当你用 GBK 写了一段文字发给你的朋友,但他却使用了 UTF-8 打开,你的文字就会变成满屏 U+FFFD 夹杂着一堆字母的乱码,当你的朋友用 UTF-8 再储存这段文本时,就会以 U+FFFD 的 UTF-8 编码 EFBFBD 来储存,重复两次形成 EFBFBDEFBFBD。当你再在 GBK 的环境中打开的话,根据 GBK 两字节一字符的编码解析,最终的结果就是:锟(EFBF)斤(BDEF)拷(BFBD)。
也就是说 ��=锟斤拷,一串�=满屏锟斤拷,经过这套行云流水的操作,你的内容就成了千万个上古神器【锟斤拷】。
烫烫烫
在 Visual Studio 中的 Debug 模式下,如果声明一个变量,但是没有初始化,微软会给未初始化的内存复制为 CC。CC 其实就是 INT3 的中断指令,所以如果在 Debug 模式下试图去执行这块未初始化的内存的话就会中断程序。
但 VS 中调试器默认的字符集是 MBCS,而 MBCS 中 CCCC 正好就是中文中的“烫”,所以显示出来就是满屏“烫烫烫”。
参考资料
维基百科
ASCII 词条、GBK 词条、锟斤拷词条
百度百科
ASCII 词条、锟斤拷词条
哔哩哔哩
林粒粒呀 2021 年 12 月 26 日期视频、柴知道 2022 年 10 月 10 日期视频
摘编百科
ASCII 码表词条